UPDATE (Mar 2024): Polished the structure of the article. Elaborated more on Accord. Updated the status quo of Accord development.
NoSQL databases have been popular for years until people realize they still want ACID support from traditional databases. In recent years, NoSQL databases with transaction support (Spanner, CockroachDB, TiDB, YugabyteDB, etc.) emerge quickly. Apache Cassandra is finally joining the party and will add distributed transaction support soon. In this post, we will first introduce distributed replication and distributed transaction to equip you with some background knowledge. Then we will introduce how Accord, the protocol for distributed transactions in Cassandra, evolves from EPaxos and why it is the first leaderless protocol that is stable for large industrial databases.
Replication v.s. Sharding
Before we start our introduction, let’s first recap two common terminologies that you often see in distributed systems: replication and sharding. They are totally different things but somewhat similar and very related.
Replication
Replication is when you store the same pieces of data into different nodes (usually on different physical machines) to ensure high availability. Most if not all databases employ some sort of replication. In general, replication is challenging (messages can be lost and nodes can fail) and you would need some consensus protocol to ensure different replicas agree on the same value and don’t diverge. Depending on the availability and consistency level they want to achieve, different databases choose different replication strategies.
Sharding
Sharding comes into place when your data cannot be fit on the single machine, or you deliberately want to distribute your data into different nodes. Sharding, a.k.a. partitioning, is supported by most if not all NoSQL databases. Distributed transactions, i.e. transactions across shards, are very challenging.
Almost every database that supports sharding also supports some sort of replication scheme, because when you have more nodes (shards), there is a higher possibility that one of them fails. This means to run distributed transactions, these databases need to take both sharding and replication into account, which can be even more challenging.
Intro to Distributed Replication
Let’s now get started by talking about replication. As we just said, to ensure different replicas see the same value, consensus algorithms are often used in databases. Note that some of these algorithms are unsafe under certain failures and some only ensure eventual consistency. Today we are only talking about the consensus algorithms that guarantee strong consistency. The word “strong consistency” is often overloaded and has different meanings in different contexts. Here, we mean that these algorithms can be used to guarantee linearizability for a single key even in presence of node failure.
Paxos (1998)
There is only one consensus protocol, and that’s Paxos.
The original paper of Paxos is very fun and worth reading. It describes an imaginary parliament as a metaphor for distributed systems. The paper even rarely mentions “computer”, and that is why people don’t understand it for years. Believe it or not, most if not all correct consensus protocols can be deduced to Paxos, so it’s a foundation paper in this field. Anyways, Paxos itself is difficult to understand, and in this post, let’s just learn the intuition behind it.
In Paxos protocol, every replica can accept a client request and propose a value for a single key. It needs to broadcast the “proposal” to other replicas (a simple majority is enough) so everyone agrees on a single value. Intuitively, it should only take only one round-trip, doesn’t it? The tricky part is that different replicas might propose different values at around the same time, and it is proved that if there is only one round, then there is no guarantee that all replicas agree on the same value. Remember, network messages can be arbitrarily delayed or lost, and nodes can fail too. Paxos is robust and safe as long as the majority of nodes are alive.
Multi-Paxos (2001) & Raft (2014)
Two round trips for a single operation sound too bad, don’t they? Multi-Paxos (proposed by the author of Paxos in 2001) and Raft (proposed by a group of researchers who were in search of an understandable consensus algorithm in 2014) reduced the two round-trips into one round-trip, greatly improving the efficiency for replicas to reach consensus. The trick is simple: we can let one replica be the leader, and require that all client write & read requests must be submitted to the leader. Remember that we said Paxos requires two round-trips because there can be concurrent proposals from different replicas? Now that we only have one leader, it can order all the requests and there is no conflict anymore.
Multi-Paxos and Raft are leader-based approaches. They successfully reduce the normal two round-trips into only one round-trip, but they have other drawbacks. First, what if the leader fails? Then the replicas must elect a new leader, and before the leader is elected, clients could experience service degradation, which is not good. Second, the leader has much more workload than other replicas, causing a workload imbalance among the nodes. Finally, a leader-based protocol may not have satisfiable latency if replicas are geographically distributed, because a client always has to talk to the leader which might be in a different data center or region.
EPaxos (2012)
Similar to Multi-Paxos and Raft, EPaxos (Egalitarian Paxos) also aims to optimize the costly two round-trips and use only one round-trip if possible. Unlike the leader-based protocols, EPaxos is leaderless. How come? Didn’t we state that concurrent transactions with multiple proposers (a replica that starts a proposal is called a proposer) could cause race conditions? Well, if you think about it, why on earth does concurrency cause conflicts? That is because when there is concurrency, it might be the case that different replicas receive requests in different orders. But does order really matter?
Apparently, there’s no “order” at the first place when concurrent requests are not conflicting (reading or writing to the same key). This is actually pretty common in production systems. Even if they are reading or writing to the same key, as long as replicas witness them in the same order, there’s no conflict of orders. This is the key idea behind EPaxos! When there is no conflict in orders, we only need one round-trip to reach a consensus — this is called the “fast path”. Note that in ordinary Paxos, you only need a simple majority of votes to reach a consensus, but here you need a super majority (we will discuss this super majority later, but usually, it’s a number that is close to 3/4). On the contrary, when there are conflicts, and some replicas (that participate in the fast path) see different orders, then a second round is needed — this is called the “slow path”. In the slow path, the coordinator has to merge all dependency chains observed by replicas and broadcast the unified dependency graph to other replicas so that replicas will execute the operations in the same deterministic order.
In leader-based approaches, when the leader fails, the service might witness suspension for some duration (can be a few seconds). Leaderless approaches like EPaxos don’t suffer this problem. As shown in the benchmark below, EPaxos still maintains almost the same throughput when there is a node failure.
Intro to Distributed Transaction
Hope you have some intuitions on distributed replication protocols. Now let’s discuss distributed transactions!
Let’s say you have shards A, B, and C, …, and each shard has three replicas: A1, A2, A3, B1, B2, B3, C1, C2, and C3, … Recall that distributed replication requires some sort of coordination so that all replicas for a single shard reach consensus. These replication protocols only require a majority of replicas to succeed.
A distributed transaction is a transaction that spans multiple shards, which also requires some sort of coordination. For example, if Alice transfers 100 dollars to Bob, then shard A that stores Alice’s account and shard B that stores Bob’s account should both succeed or fail. Note that a multi-shard transaction requires every shard to succeed, not just the majority.
It’s all about Abstraction: 2PC atop Replication
We all know how abstraction has deeply influenced software engineering. Abstraction is a fundamental concept where higher layers operate independently of the lower layers. Does it apply here? Can you build distributed transaction on top of distributed replication, and treat each replica set as a whole? The good answer is yes, and that’s what most distributed DBs are doing! For a while, let’s forget about replication, and conceptually assume every shard only sits on one machine.
The common approach for distributed transaction is called 2PC: Two-phase commit. It’s commonly used in data systems to make sure a transaction is either committed across all involved nodes (shards) or aborted. In the first phase (PREPARE), all parts vote on whether the transaction can proceed. In the second phase (COMMIT), based on the votes, the transaction is either completed by all parts or aborted, ensuring consistency across the system. Distributed transaction sounds simple, doesn’t it? Well, in practice, it’s complicated. For example, if there are conflicting transactions (transactions that have overlapping read or write keys), we need to ensure those transactions are executed in the same order across shards.
Almost all production databases build distributed transactions (if any) on top of the replication layer. That is, “replicas” are “abstracted” and agnostic to the algorithms for transactions. This makes building distributed transaction algorithms easier, but it is also costly as you have two separate types of coordination (replication layer and transaction layer). The below figure shows the common architecture for distributed transactional databases.
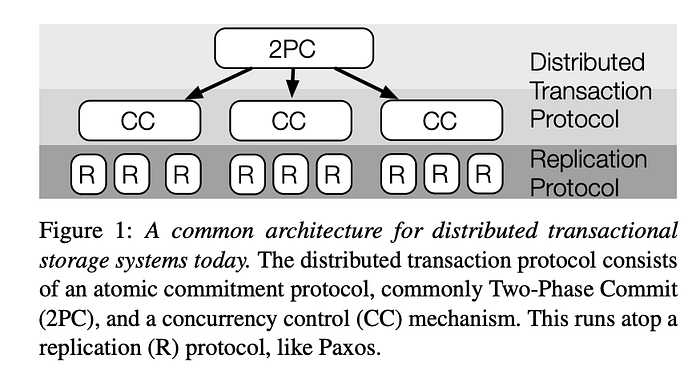
Now let’s outline the approaches of a few popular databases that support distributed transactions. All of those databases either use 2PC, or a variant to coordinate cross-shard transactions. The biggest difference between them is how they order transactions globally. Please note that this is only to my best knowledge, and databases, in general, can evolve quickly (who would have anticipated ACID support in Cassandra?), so please take the following summary with a grain of salt.
FaunaDB and FoundationDB use a single leader to order conflicting transactions. This is great because it is (relatively) easy to implement and straightforward to understand, but it is impractical for super large clusters with hundreds of nodes. TiDB uses a global timestamp oracle to assign and distributed timestamps to transactions. Again, this timestamp oracle makes horizontal scaling and geo-replication hard if not impossible.
Many other databases use multiple leaders, but the biggest challenge is how to ensure a consistent order for concurrent transactions that span different shards. A natural question to ask is: why not just use wall clocks to determine the order of transactions? The answer is that wall clocks (even with NTP synchronization) are inaccurate! Your laptop might have a few milliseconds or even seconds of time difference compared to someone else’s laptop. In a highly concurrent environment, even a clock drift of a few milliseconds could cause serious inconsistencies.
CockroachDB uses hybrid logical clocks (vector clock + wall clock) to determine orders. This works great except that it cannot provide “strict serializability”, sometimes also known as “linearizability”. Consequently, your queries can time travel in the sense that your read request does not necessarily return the latest value.
Google’s Spanner is a special one. It also uses physical time, but it does not suffer from the clock drift problem. Why? The key is that they use special hardware, i.e. atomic clocks + GPS to ensure the clock drift is very small (guaranteed to be less than 10 milliseconds across regions). The time difference is not entirely negligible but it is small enough that they could use software approaches to overcome it (to simply wait, wait for a grace period before commit). Of course, this is expensive and it seems only Google has this offering.
Wait… if replication layer is abstracted away from transaction layer, why did we spend so much time discussing distributed replication? You’ll find the answer in the next section.
A different Approach: Intro to Accord
Let’s talk about a completely different approach. Recall that in replication protocols, operations need to be coordinated. Also recall that in distributed transactions context, multi-shard transactions need to be coordinated. Do they sound similar? Since replication and transactions have similar requirements, can we use a single protocol to achieve both?
Co-design of Transaction and Replication
The answer is yes, and let’s break abstraction! The authors of TAPIR (SOSP 2015) realize for multi-shard transactions, it is sufficient for the transaction layer to enforce consistency. In other words, it is a waste for the replication layer to achieve single-shard consistency. By co-designing replication and transaction, TAPIR achieves similar linearizability guarantee with Spanner, but with better throughput and latency. TAPIR still uses 2PC, but it’s not replication layer agnostic anymore. Apparently this decoupling makes engineering very difficult and hard to understand. Is there any production system that implements TAPIR? Not that I am aware of.
ACCORD can do better
This co-design principle of TAPIR inspired other works like Janus [3] (OSDI 2016) and Tempo [4] (2021). Similar to those protocols, Accord uses an EPaxos-like approach to track conflicting arrival orders of both different transactions across shards and the same transaction within a shard. The authors from Cassandra community claim that Accord is the first leaderless protocol that is stable for large industrial databases, and the first protocol that offers strict serializable transactions across regions in a single wide-area round-trip.
The key to ACCORD’s optimal performance is its engineering optimization to increase the chance of fast-path success. I strongly recommend you to read the Accord white paper which contains a detailed outline of the protocol but here is a summary of two important improvements that Accord does over its prior systems including TAPIR.
Flexible Fast-path Electorates
You may remember we said earlier that fast-path quorum requires a super majority rather than a simple majority. Different leaderless protocols have different requirements on this number, but for Accord, super majority is ⌈3f/2⌉ + 1 for replica set size 2f+1. Why is it the case? Here is an intuitive explanation:
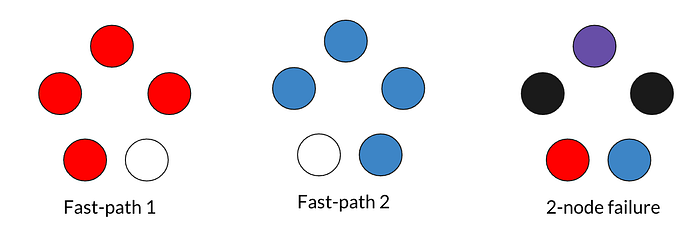
In the 5 replica set (f = 2) as shown in the picture above, the fast-path quorum must be at least 4, so that under 2-node failure (black nodes on the right), there should still be at least 1 node (purple node on the right) from the simple quorum that is part of both fast-path1 and fast-path2 to recover. If a fast-path only requires 3 nodes, then under 2-node failure, there is a chance that no active node from a simple quorum knows both fast-path1 and fast-path2.
Super majority is a bad requirement because it makes the chance of falling back to slow path high. In the above example, a failure of two arbitrary nodes will make any fast-path impossible. To address this problem, Accord proposes a concept called flexible Fast-path Electorates. The idea is: what if we exclude 2 nodes from the fast-path quorum electorate?
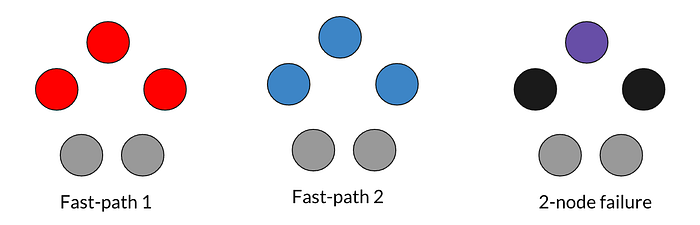
We could dynamically adjust the fast-path electorates based on an estimate of network latency and node conditions. Let’s say we exclude the two bottom (grey) nodes from the fast-path electorate, as shown in the graph above. It could be because those two nodes belong to less beefy machines, or because they are in a different data center than the others. Now we only need 3 nodes to be on the fast path. Even if two nodes fail (black nodes on the right), we still have one overlapping node (purple node on the right) to recover both fast paths. In the best case, even under two-node failure (grey nodes), we can still achieve a fast path. This makes Accord more efficient than EPaxos because it has a lower chance of falling back to slow-path (two round-trips) under node failure.
Message Reorder Buffer
When we discussed EPaxos, we said if the voting replicas don’t witness the same ordering of transactions, then a second round (slow-path) is needed so that the coordinator could broadcast the total ordering (dependency graph). If we could reduce the chance of different replicas witnessing different ordering, then there is a higher chance of achieving a fast-path quorum. The trick used by Accord is to deliberately buffer messages until some estimated skew + latency expires.
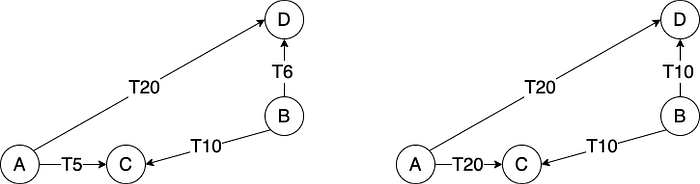
For example, as shown in the graph above, if both node A and node B start two transactions at T0, then nodes C and D will see different orders of events because C is closer to A than B while D is closer to B than A. In Accord, the max time that any replica will receive the message from A can be estimated, which is T20 in this example. All replicas (C and D in this case), upon receiving the message from A, will buffer it until T20. Similarly, they will buffer the message from B until T10. This way, both C and D will observe that message from B comes before the message from A. This idea comes from the paper EPaxos revisited, but Accord makes some engineering optimizations, which we will not discuss in detail here.
What about 2PC?
One Final thing: we have mentioned 2PC a lot throughout this article, but if you read Accord white paper, you will be surprised to see it doesn’t ever mention 2PC. Didn’t we mention earlier that all participating shards need to vote unanimously to decide whether the transaction shall succeed or abort, which is why we need 2PC?
Let’s rethink about why transactions could abort. First, in traditional RDBMS, abort could happen due to system constraints like foreign key constraints, but those constraints usually don’t exist in NoSQL. Second, a transaction may need to abort if it conflicts with another transaction. In Accord, conflicted transactions are ordered ahead of execution, so there’s no abort during execution.
Not using 2PC does not necessarily mean Accord can achieve a distributed transaction in a single phase. Accord does have three phases (PreAccept, Accept and Commit), among which Accept phase can be skipped under fast-path success.
What’s next for Cassandra
The Accord prototype, a separate Java repo, has seen active development in the past 2+ years. It’s also being integrated to Cassandra and let’s hope it could be included in Cassandra 5.0 release. Back in 2022 I thought it would be released in a few months, but apparently that didn’t happen :P
Thanks for your patience in reading such a long post! I hope it sheds some light on the field of distributed transactions. If you are interested in more details about the Accord protocol, check out this Cassandra Enhancement Protocol. Finally, I am not the author of Accord, so this article is completely based on my own understanding. Please let me know if you find anything unclear or wrong.
References
- https://cwiki.apache.org/confluence/display/CASSANDRA/CEP-15%3A+General+Purpose+Transactions
- https://irenezhang.net/papers/tapir-sosp15.pdf
- https://www.usenix.org/conference/osdi16/technical-sessions/presentation/mu
- https://dl.acm.org/doi/10.1145/3447786.3456236
- http://charap.co/reading-group-special-session-fast-general-purpose-transactions-in-apache-cassandra/
- https://www.youtube.com/watch?v=YAE7E-QEAvk
- https://www.synergylabs.org/courses/15-440/lectures/12-replication.pdf
- https://dl.acm.org/doi/abs/10.1145/3335772.3335939
- https://www.microsoft.com/en-us/research/publication/paxos-made-simple/
- https://www.usenix.org/conference/atc14/technical-sessions/presentation/ongaro
- https://dl.acm.org/doi/abs/10.1145/2517349.2517350
- http://muratbuffalo.blogspot.com/2022/02/efficient-replication-via-timestamp.html
- https://www.usenix.org/conference/nsdi21/presentation/tollman
